Abstract
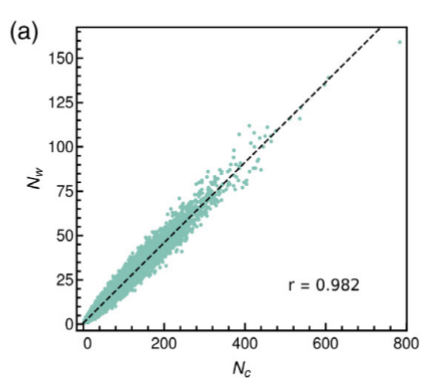
Hidden structural patterns in written texts have been subject of considerable research in the last decades. In particular, mapping a text into a time series of sentence lengths is a natural way to investigate text structure. Typically, sentence length has been quantified by using measures based on the number of words and the number of characters, but other variations are possible. To quantify the robustness of different sentence length measures, we analyzed a database containing about five hundred books in English. For each book, we extracted six distinct measures of sentence length, including the number of words and number of characters (taking into account lemmatization and stop words removal). We compared these six measures for each book by using (i) Pearson’s coefficient to investigate linear correlations; (ii) Kolmogorov–Smirnov test to compare distributions; and (iii) detrended fluctuation analysis (DFA) to quantify auto–correlations. We have found that all six measures exhibit very similar behavior, suggesting that sentence length is a robust measure related to text structure.